1.Apollo
统一管理配置信息,增强配置管理的服务能力。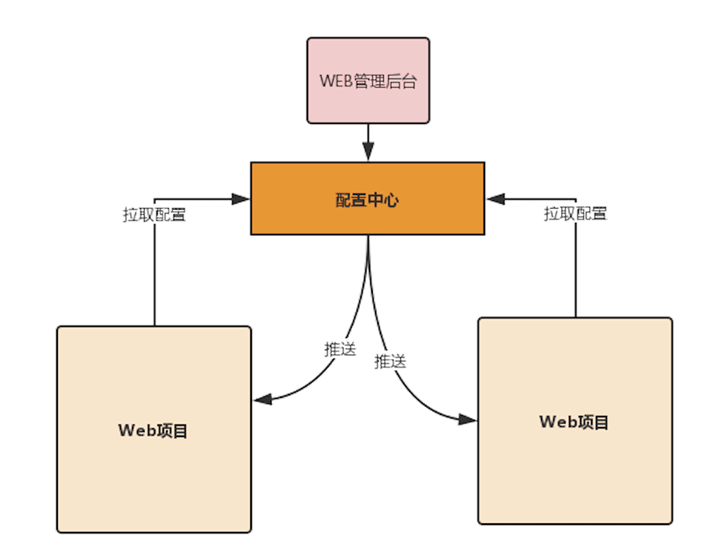
使用配置中心管理配置后,可以将配置信息从项目转移到配置中心,一般一个项目会有一个唯一的标识ID,通过这个ID从配置中心获取对应的配置内容。
- 拉取
项目在启动的时候通过配置中心拉取配置信息。 - 推送
在配置中心修改配置后,可以实时地推送给客户端进行更新。
解决的问题:每个节点都要重启、格式不规范、容易被错改、没有历史记录、安全性不高
1.1 主要功能
- 统一管理不同环境、不同集群的配置
- 配置修改实时生效,即热发布功能
- 版本发布管理
- 灰度发布
- 权限管理、发布审核、操作审计
- 提供Java和.Net原生客户端,轻松集成、操作简单
- 提供开放平台API
- 部署简单
Apollo 和 Spring Cloud Config 对比![]()

1.2 概念介绍
应用
应用指项目,标识用appId来指定,Spring Boot项目中建议直接配置在application.yml中。环境
Apollo客户端在运行时除了需要知道项目当前的身份标识,还需要知道当前项目对应的环境,从而根据环境去配置中心获取对应的配置。可以通过Java System Property或配置文件指定,目前支持的环境有Local、DEV、FAT(测试环境)、UAT(集成环境)、PRO(生产环境)。集群
不同的集群可以有不同的配置文件,可以通过Java System Property或配置文件来指定。命名空间
可以用来对配置做分类,不同类型的配置存放在不同的命名空间中,如数据库配置文件、消息队列配置、业务相关配置等。命名空间还可以让多个项目共用一份配置,如Redis集群。权限控制
1.3 架构设计
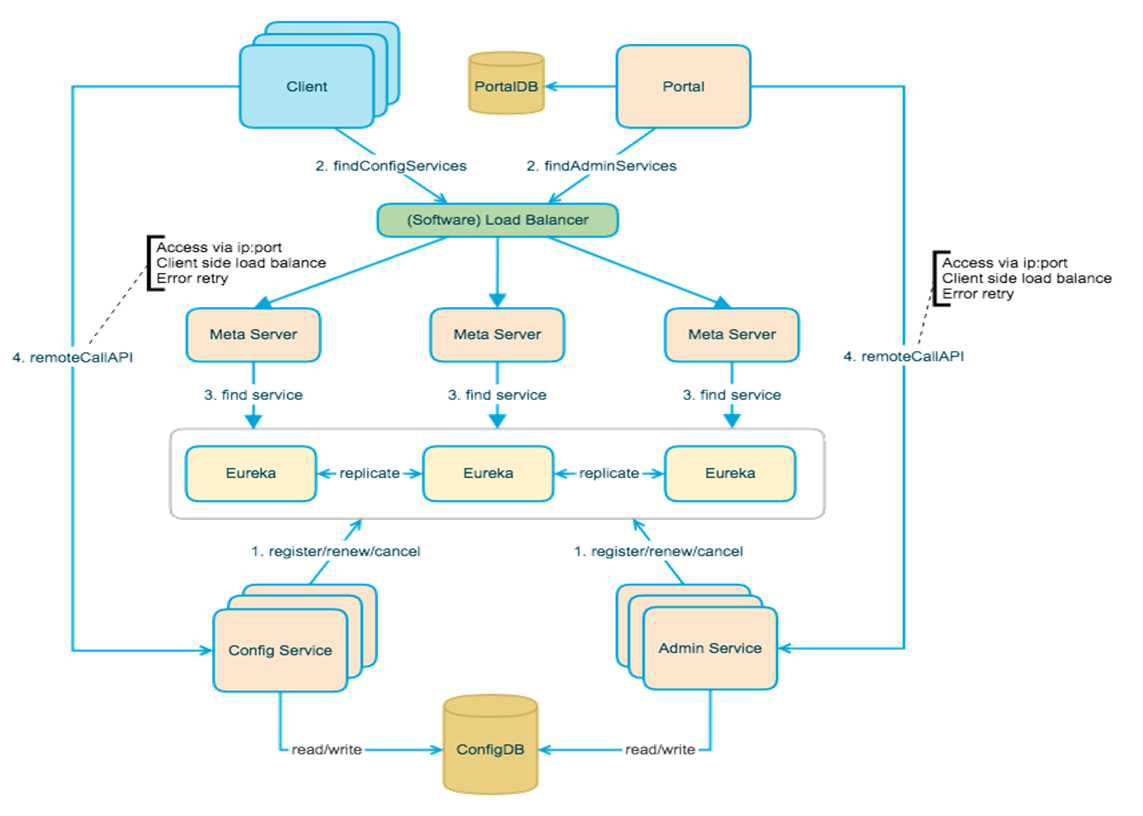
Config Service
服务于Client对配置的操作,提供配置的查询、更新接口(基于Http long polling)Admin Service
服务于后台Portal(Web管理端),提供配置管理接口Meta Server
Meta Server是对Eureka的一个封装,提供了HTTP接口获取Admin Service和Config Service的服务信息。部署时和Config Service是在一个JVM进程中的,所以IP、端口和Config Service一致。Eureka
用于提供服务注册和发现,Config Service和Admin Service都会向Eureka注册服务。Eureka在部署时和Config Service在一个JVM进程中,即Config Service包含了Meta Server和Eureka。Portal
后台Web界面管理配置,通过Meta Server获取Admin Service服务列表(IP+Port)进行配置的管理,客户端做负载均衡。Cilent
Apollo提供的客户端,用于项目中对配置的获取、更新。通过Meta Server获取Config Service服务列表(IP+Port)进行配置的管理,客户端内做负载均衡。
工作流程:
- 注册、续约、取消,也就是服务注册的操作,Config Service和Admin Service都会注册到Eureka中。
- 服务发现的逻辑,Client需要指定所有的Config Service,Portal需要知道所有的Admin Service,然后才能发起对应的操作。查找服务列表是通过负载进行转发到Meta Server.
- Meta Server去Eureka中获取对应的服务列表。
- 当获取到对应的服务信息后,就可以直接发起远程调用了。
推送设计: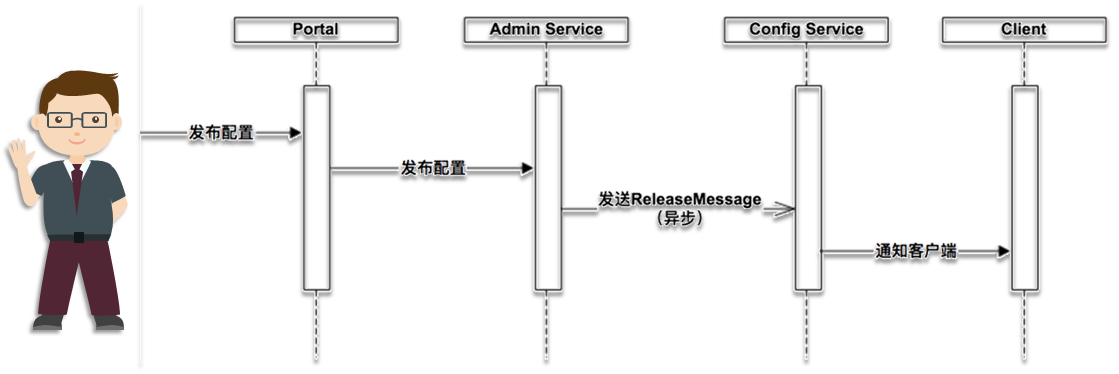
在Portal中进行配置的编辑和发布操作后,Portal会调用Admin Service提供的接口进行发布操作。Admin Service收到请求后,发送ReleaseMessage给各个Config Service,通知Config Service配置发生了变化。Config Service收到ReleaseMessage后,通知对应的客户端,基于HTTP长连接实现。
消息设计: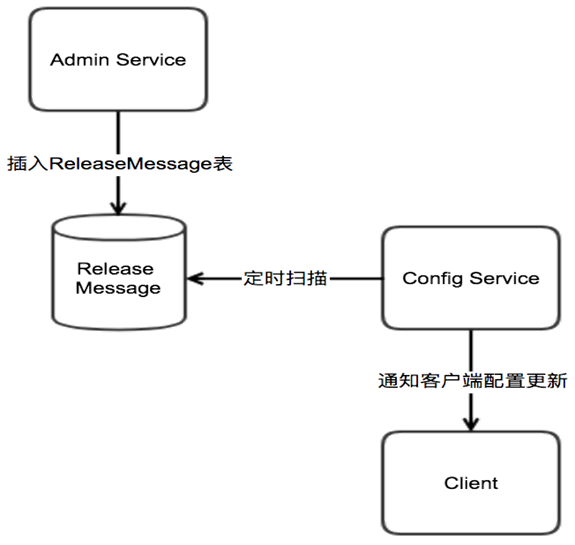
ReleaseMessage消息是通过MySQL实现了一个简单的消息队列。Admin Service在配置发布后会往ReleaseMessage表插入一条消息记录,Config Service会启动一个线程定时扫描ReleaseMessage表,去查看是否有新的消息记录。Config Service发现有新的消息记录,那么就会通知所有的消息监听器,消息监听器得到配置发布的信息后,则会通知对应的客户端。
客户端设计: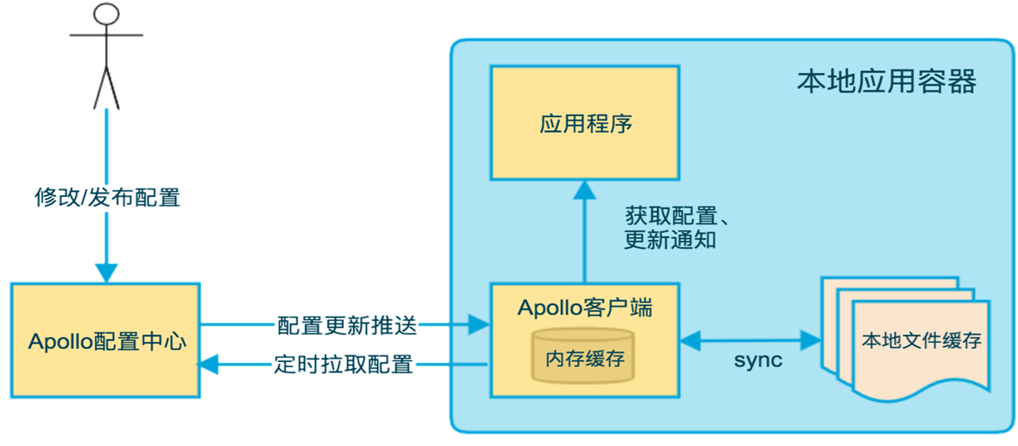
客户端和服务端保持了一个长连接,编译配置的实时更新推送。定时拉取配置是客户端本地的一个定时任务,默认5分钟1次,也可以通过在运行时指定System Property:apollo.refreshInterval来进行覆盖,单位是分钟,采用推送+定时拉取的方式就等于双保险。客户端从Apollo配置中心服务端获取到应用的最新配置后,会保存在内存中。客户端会把从服务取到的配置在本地文件系统中缓存一份,当服务或网络不可用时可以使用本地配置,也就是本地开发模式env=Local。
2.分布式链路跟踪
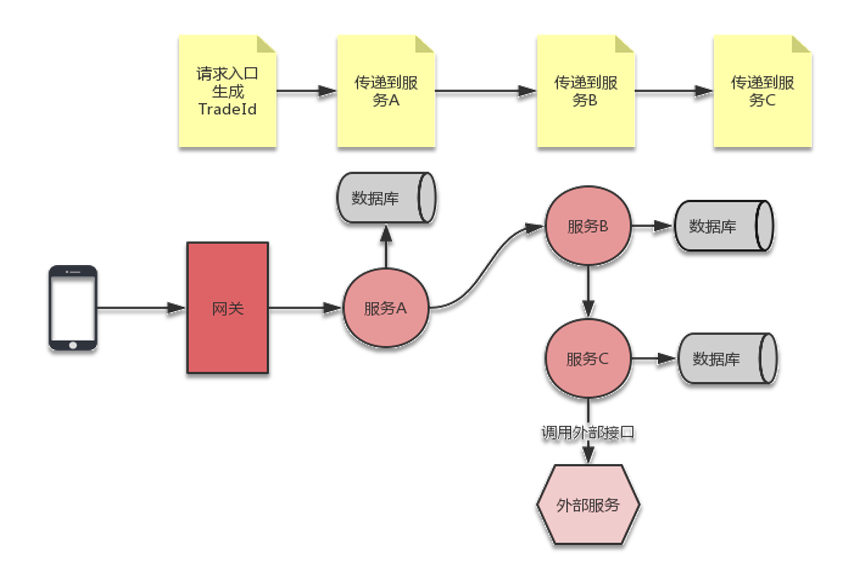
分布式链路跟踪的关键在于如何将请求经过的服务节点都关联起来。
2.1 核心概念
Span
基本工作单元,如发送RPC请求是一个新的Span、发送HTTP请求是一个新的Span、内部方法调用也是一个新的Span。Trace
一次分布式调用的链路信息,每次调用链路信息都会在请求入口处生成一个TraceId。Annotation
用于记录事件的信息。在Annotation中会有CS、SR、SS、CR这些信息。CS
Client Sent,客户端发送一个请求,这个Annotation表示Span的开始。SR
Server Received,服务端获得请求并开始处理,用SR的时间减去CS的时间即网络延迟时间。SS
Server Sent,在请求处理完成时将响应发送回客户端,SR-SS,即服务端处理请求所需的时间。CR
Client Recevied,表示Span结束,客户端从服务端收到响应,CR-CS,即全部时间。
2.2 请求追踪过程分解
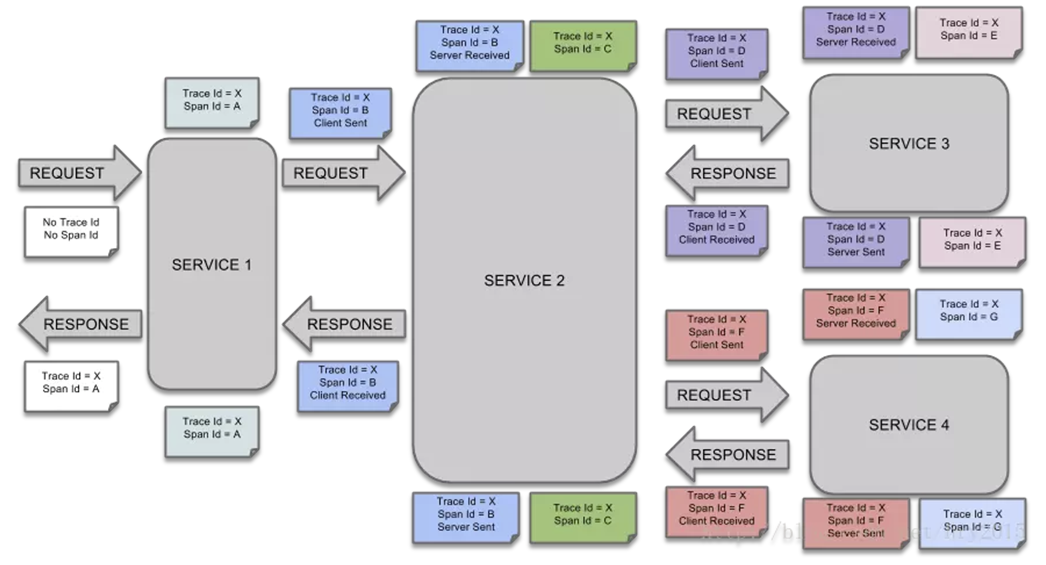
- 当一个请求访问SERVICE1时,此时没有Trace和Span,会生成Trace和Span,如图所示生成Trace ID是X,Span ID是A。
- 接着SERVICE1请求SERVICE2,这是一次远程请求,会生成一个新的Span,Span ID为B,Trace ID不变还是X。Span B处于CS状态,当请求到达SERVICE2后,SERVICE2有内部操作,生成了一个新的Span,Span ID为C,Trace ID不变。
- SERVICE2处理完后向SERVICE3发起请求,生成新的Span,Span ID为D,Span D处于CS状态,SERVICE3接收请求后,Span D处于RS状态,同时SERVICE内部操作也会生成新的Span,Span ID为E。
- SERVICE3处理完后,需要将结果响应给调用方,此时Span D处于SS状态,当SERVICE2收到响应后,Span D处于CR状态。
一次请求会经过多个服务,会产生多个Span,但Trace ID只有一个。
2.3 Spring Cloud Sleuth
- 可以添加链路信息到日志中
- 链路数据可直接上报给Zipkin
- 内置了很多框架的埋点,如Zuul、Feign、Hystrix
2.4 Zipkin
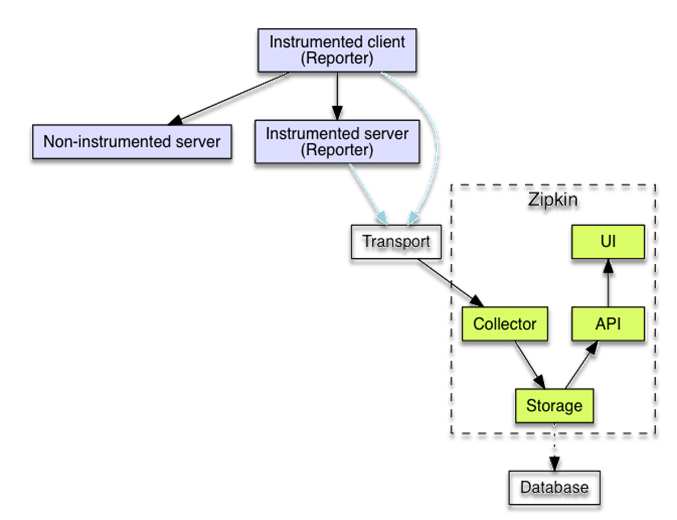
收集数据、查询数据。
Collector
Zipkin的数据收集器,进行数据验证、存储。Storage
存储组件,Zipkin默认在内存中存储数据,数据落地的话支持ElasticSearch和MySQL。Search
Zipkin的查询API,用于查找和检索数据,主要使用者为Web UI。Web UI
提供可视化的操作界面,直观的查询链路跟踪数据。
链路跟踪的信息会通过Transport传递给Zipkin的Collector,Transport支持的方式有HTTP和MQ进行传输。
2.5 Sleuth关联整个请求链路日志
集成Spring Cloud Sleuth后,会在原始的日志加上一些链路的信息。
application name
应用名称,即application.yml里的spring.application.name参数配置的属性。traceId
为请求分配的唯一请求号,用来标识一条请求链路。spanId
基本的工作单元,一个请求可以包含多个步骤,每个步骤有自己的Span ID,一次请求只有一个Trace ID和多个Span Id。export
布尔类型,表示是否将该信息输出到Zipkin进行收集和展示。
2.6 使用技巧
抽样采集数据
spring.sleuth.sampler.probability=10
请求次数:Zipkin数据条数=10:1RabbitMQ代替HTTP发送调用链路数据
删除配置spring.zipkin.base-url,在启动Zipkin服务时指定RabbitMQ信息:1
java -DRABBIT_ADDRESSES=192.168.10.124:5672 -DRABBIT_USER=admin -DRABBIT_PASSWORD=123456 -jar zipkin.jar
ElasticSearch存储调用链数据
启动Zipkin的时候指定存储类型为ES,指定ES的URL信息:1
java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://localhost:9200 -jar zipkin.jar
手动埋点检测性能
Hystrix埋点分析
3.微服务安全认证
3.1 常用的认证方式
session
用户登陆后将信息存储在服务端,客户端通过cookie中的sessionId来标识对应的用户。缺点:
- 服务端需要保存每个用户的登录信息,如果用户量非常的,服务端的存储压力也会增大。
- 多节点时,通过负载均衡器进行转发,session可能会丢失。
解决办法:
session复制,Nginx可以设置黏性Cookie来保证一个用户的请求只访问同一个节点;session集中存储,如存储在Redis中。HTTP Basic Authentication
HTTP基本认证,客户端会在请求头中增加Authorization,Authorization是用户名和密码Base64加密后的内容,服务端获取Authorization Header中的用户名与密码进行验证。Token
与HTTP Basic Authentication类似,与session不同,session只是一个key,会话信息存储在服务端。而Token中会存储用户的信息,然后通过加密算法进行加密,只有服务端才能解密,服务端拿到Token后进行解密获取用户信息。
3.2 JWT认证
简介:
JWT(JSON Web Token)
如用户登录时,基本思路就是用户提供用户名和密码给认证服务器,服务器验证用户提交信息的合法性;如果验证成功,会产生并返回一个Token,用户可以使用这个Token访问服务器上受保护的资源。
JWT由三部分构成:头部(Header)、消息体(Payload)、签名(Signature)
1 | token = encodeBase64(header) + '.' + encodeBase64(payload) + '.' + encodeBase64(signature) |
头部信息:令牌类型、签名算法
1 | { "alg": "HS256", "typ": "JWT" } |
消息体:应用需要的信息,如用户的id
1 | {"id": "1234567890", "name": "John Doe"} |
签名:用来判断消息在传递的路径上是否被篡改
1 | HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret) |
JWT认证流程: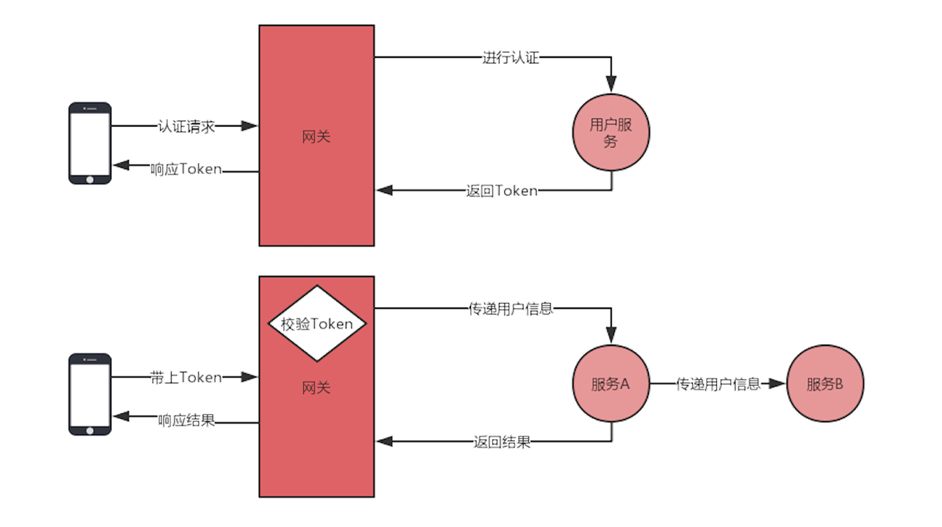
客户端需要调用服务端提供的认证接口来获取 Token。获取 Token 的流程如图所示,客户端会首先发起一个认证的请求到网关,网关会将请求转发到后端的用户服务中,在用户服务中验证身份后,就会根据用户的信息生成一个 Token 返回给客户端,这样客户端就获取了后面请求的通行证。然后,客户端会将获取的 Token 存储起来,在下次请求时带上这个 Token,一般会将 Token 放入请求头中进行传递。当请求到达网关后,会在网关中对 Token 进行校验,如果校验成功,则将该请求转发到后端的服务中,在转发时会将 Token 解析出的用户信息也一并带过去,这样在后端的服务中就不用再解析一遍 Token 获取的用户信息,这个操作统一在网关进行的。如果校验失败,那么就直接返回对应的结果给客户端,不会将请求进行转发。
在网关中,验证过滤器会对 /oauth/token 这个认证 API 进行放行,不进行验证。
用户信息的全局传递扩展:
不需要加参数,直接通过请求头进行传递,在服务内部通过ThreadLocal进行上下文传递。主要流程:从网关传递到后端服务,后端服务接受数据后存储到ThreadLocal中,服务会调用其它服务,如果用Feign调用可以利用Feign的拦截器传递数据,如果用RestTemplate的拦截器传递数据也一样。
3.3 Token的使用
Token注销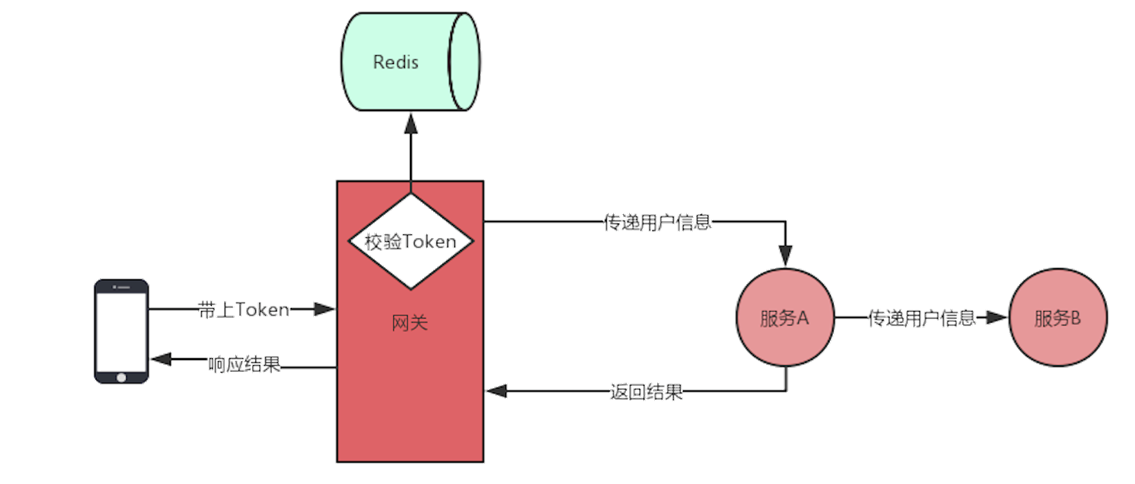
Token的有效期存储在Token本身中,只有解析出Token的信息,才能获取到Token的有效时间,不能修改。Token的有效期越短,安全性越高。还可以在用户退出登录时,进行Token的注销操作,如将注销的Token放入Redis中进行一层过滤,即在网关中验证Token有效性时先从Redis中判断Token是否存在,如果存在,直接拦截。Token放入Redis的过期时间一般会设置为Token剩余的有效时间。
使用建议
- 设置较短(合理)的过期时间
- 注销的Token及时清除(放入Redis中做一层过滤)
- 监控Token的使用频率
- 核心功能敏感操作可以使用动态验证(验证码)
- 网络环境、浏览器信息等识别
- 加密密钥支持动态修改
- 加密密钥支持动态修改
3.4 内部服务之间的认证
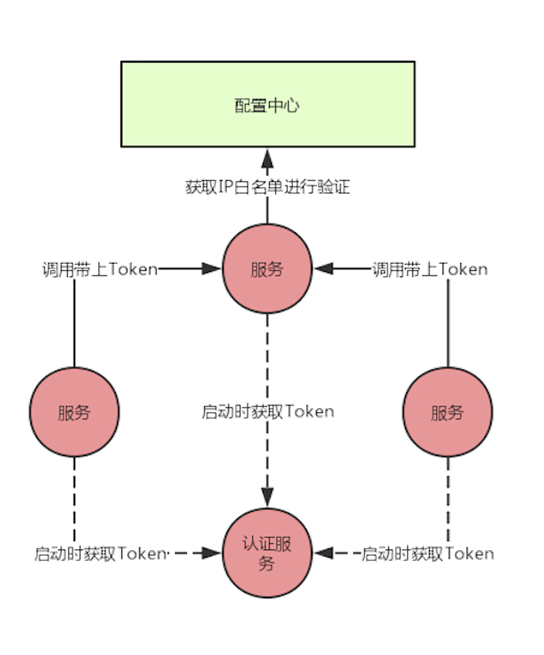
IP白名单
如用户服务只能某些IP或IP段访问,IP白名单可以采用配置中心来存储,具备实时刷新的能力。内部同样使用Token进行验证
服务在启动时就可以在统一的认证服务中申请Token,申请需要的认证信息可以放在配置中心。这样服务启动时就有了能够访问其他服务的Token,在调用时带上Token,被调用的服务中进行Token的校验。
对于Token的失效更新:- 在请求时如果返回的Token已经失效,那么可以重新获取Token后再发起调用,这种在并发量大时需要加锁,不然会发生同时申请多个Token的情况。
- 定时更新,如Token有效期1个小时,那么定时任务可以50分钟更新一次。

