1.Eureka
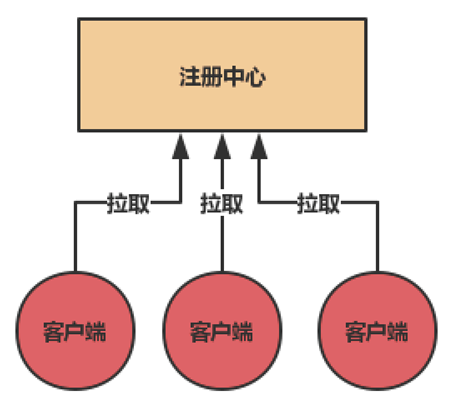
如果需要实现完整的服务注册与服务发现的功能,我们需要有注册中心来统一存储和管理服务信息,应用程序需要将自身的信息注册到注册中心,也就是服务提供者和服务消费者的信息。整个过程中包含的操作有注册、拉取、心跳、剔除等动作。
- 注册中心:用来集中存储管理服务信息。
- 服务提供者:通过API供其他方调用服务。
- 服务消费者:需要调用其他方的API获取服务。
项目启动后Eureka Client会向Eureka Server发送请求,进行注册,并将自身信息发送给Eureka Server。注册成功后,每隔一定的时间,Eureka Client会向Eureka Server发送心跳来续约服务,汇报健康状态。如果客户端长时间没有续约,那么Eureka Server大约在90秒内从服务器注册表中清除客户端的信息。应用程序停止时Eureka Client会通知Eureka Server移除相关信息,信息移除成功后,对应的客户端会更新服务的信息,这样就不会调用已经下线的服务,但操作具有延迟,有可能会调到已经失效的服务,所以在客户端会开启失败重试功能来避免这个问题。Eureka Serve集群保证高可用,Eureka Server没有集成其它第三方存储,而是存储在内存中。所以Eureka Server之间会将注册信息复制到集群中的Eureka Serve的所有节点。这样数据才是共享状态,任何的Eureka Client都可以在任何一个Eureka Server节点查找到注册信息。
1.1 Eureka注册表
Eureka的注册信息是存储在ConcurrentHashMap中的,Map的key是服务名称,value是一个Map。value的Map的key是服务实例的ID,value是Lease类,Lease中存储了实例的注册时间、上线时间等信息,还有具体的实例信息,如IP、端口、健康检查的地址等信息。
Eureka将注册的服务信息存储在内存中的原因:性能高;部署简单,不需要依赖于第三方存储。
劣势:扩容难度高,每个Eureka Server都全量的存储一份注册表,假如存储空间不够了,需要扩容,那么所有的Eureka Server节点都必须扩容,必须采用的内存配置。
Eureka核心操作主要有注册、续约、下线、移除,接口为com.netflix.eureka.lease.LeaseManager,这些操作都是针对注册表的操作,也就是Map的操作。
1.2 自我保护机制
自我保护机制是为了避免因网络分区故障而导致服务不可用的问题。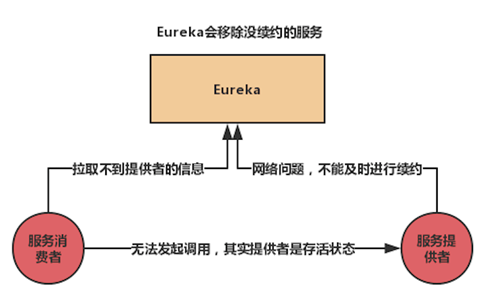
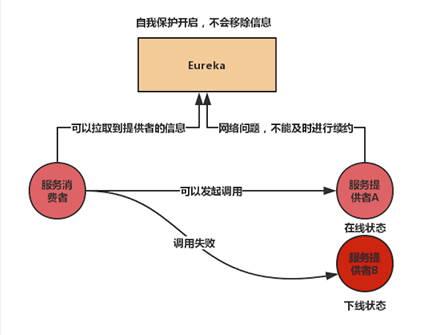
自我保护机制带来的问题:若服务提供者B真的下线了,由于Eureka Serve自我保护机制打开,不会移除任务信息,当服务消费者对服务提供者B进行调用时,就会出错。出现某些有问题的实例没能及时移除掉的情况,服务消费者可以通过Ribbon来进行重试,保证调用能够成功。
自我保护开启的条件:AbstractInstanceRegistry中有两个字段,numberOfRenewsPerMinThreshold(期望最小每分钟能够续租的次数)、expectedNumberOfClientsSendingRenews(期望的服务实例数)。假如有10个实例,每个实例每分钟续约2次,那么10x2x0.85=17,即每分钟至少有17次续约才是正常的。
1.3 健康检查
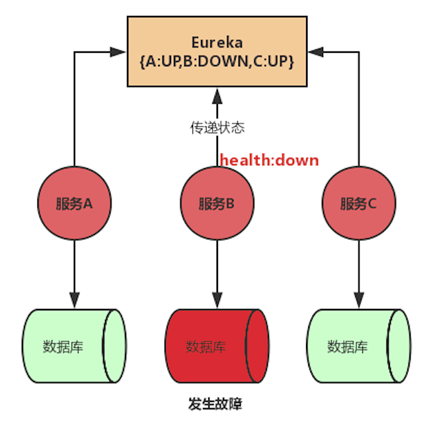
Eureka Client会定时发送心跳给Eureka Server来证明自己是否处于健康的状态。但某些场景下,服务处于存活状态,却已经不能对外提供服务,如数据库出问题了,但心跳正常,客户端在请求时还会请求到这个出问题的实例。可以在项目中集成Actuator,统一管理应用的健康状态,将这个状态反馈给Eureka Server。
2.Ribbon
2.1 负载均衡
负载均衡是一种基础的网络服务,它的核心原理是按照指定的负载均衡算法,将请求分配到后端服务集群上,从而为系统提供并行处理和高可用的能力。
集中式负载均衡:在消费者和提供者中间使用独立的代理方式进行负载,有硬件的负载均衡器,如F5,也有软件,如Nginx。客户端不需要关心对应服务实例的信息,只需要与负载均衡器进行交互,服务实例扩容或者缩容,客户端不需要修改任何代码。
![]()
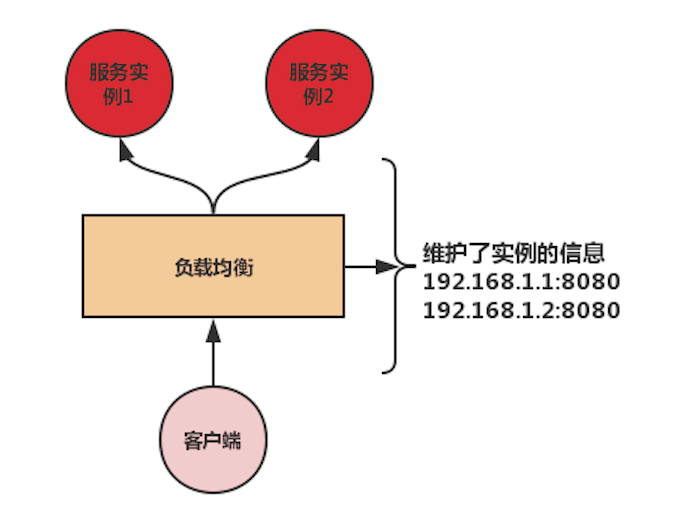
客户端负载均衡:需要自己维护服务实例信息,然后通过某些负载均衡算法,从实例中选取一个实例,直接进行访问。
区别:对服务实例信息的维护。集中式负载均衡的信息是集中进行维护的,如Nginx,都会在配置文件中进行指定。客户端负载均衡的信息是在客户端本地进行维护的,可以手动配置,最常见的是从注册中心拉取。
2.2 Ribbon
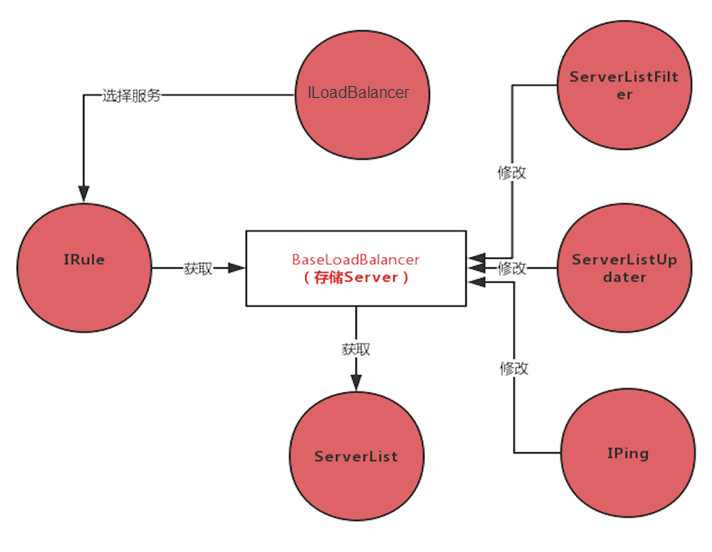

使用方式:
- 原生API
- Ribbon+RestTemplate
- Ribbon+Feign
通过给加了@LoadBalanced的RestTemplate添加拦截器,拦截器中通过Ribbon选取服务实例,然后将请求地址中的服务名称替换成Ribbon选取服务实例的IP和端口。
2.3 负载均衡策略
- 内置负载均衡策略
- RoundRobinRule:轮询算法
- RandomRule:随机算法
- BestAvailableRule:选择一个最小的并发请求server,如果有A、B两个实例,当A有4个请求正在处理中,B有2个,下次请求会选择B,适用于服务所在机器配置相同的情况。
- WeightedResponseTimeRule:根据请求的响应时间计算权重,如果响应时间越长,那么对应的权重越低,权重越低的服务器,被选择的可能性就越低。
- 自定义负载均衡算法
- 实现IRule接口或继承AbstractLoadBanlancerRule
- 实现choose方法
- 指定Ribbon的算法类
使用场景:
- 定制与业务更匹配的策略。
- 灰度发布
- 多版本隔离
- 故障隔离
2.4 饥饿加载模式
Ribbon在进行客户端负载均衡时并不是启动时就加载上下文,而是第一次请求时才去创建的,因此第一次调用会比较慢,有可能会引起调用超时。可以指定Ribbon客户端的名称,在启动时加载这些子应用程序上下文。
初始化后进行了缓存操作,getContext()方法中,如果在contexts中不存在才会创建,创建时会用synchronized加锁,并进行二次判断,防止并发下出现创建多次的问题,最后进行增加操作。如果有的话就直接从contexts获取返回。contexts就是一个ConcurrentHashMap。
3.Hystrix
3.1 服务雪崩
微服务架构下,会存在服务之间相互依赖调用的情况,当某个服务不可用时,很容易因为服务之间的依赖关系使故障扩大,甚至造成整个系统不可用,这种现象称为服务雪崩效应。
产生原因:
服务提供者
代码的Bug问题,由于某些代码导致CPU飙升,将资源耗尽等;服务器出现问题,磁盘出问题,导致数据读写特别慢,拉高了响应时间;慢SQL语句问题;请求量太大,超出系统本身的承受能力。服务消费者
同步调用等待结果导致资源耗尽;自己既是服务消费者也是服务提供者。
解决方案:
服务提供者
代码Bug问题:测试、Code Review等方式;慢SQL问题:数据库性能优化;服务器硬件故障问题:加大运维粒度,通过监控等手段提前预防;请求量超出承受能力:扩容或限流服务消费者
资源隔离、快速失败。
3.2 容错实现
设计原则: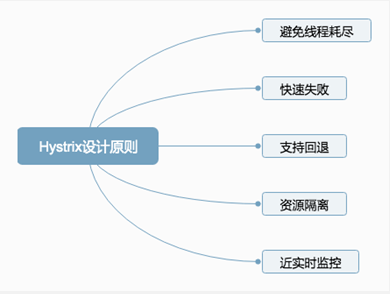
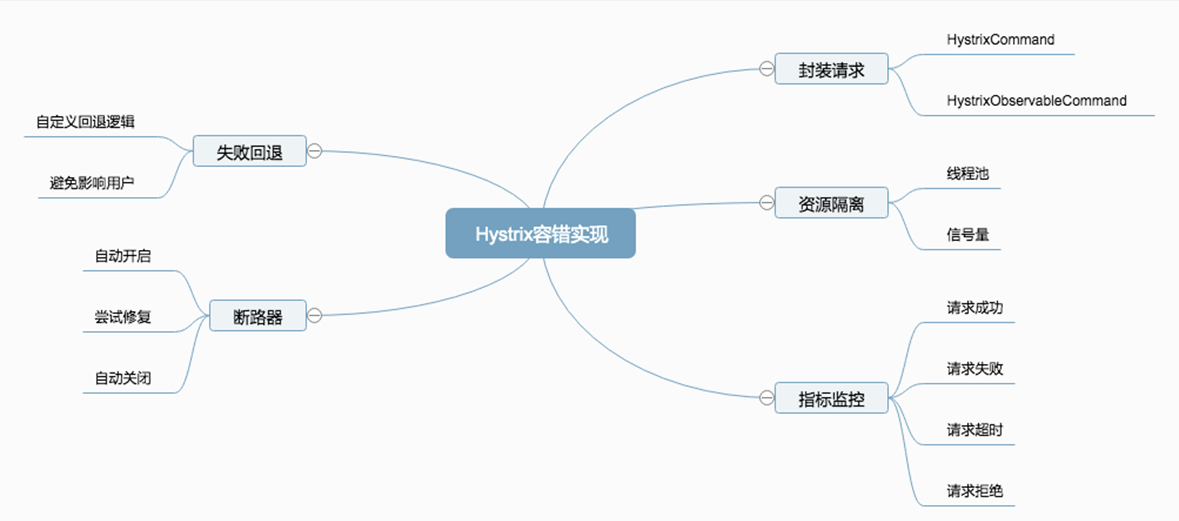
- 封装请求:将用户的操作进行统一封装,目的在于进行统一控制。
- 资源隔离:将对应的资源按照指定的类型进行隔离,如线程池和信号量。
- 失败回退:备用方案,当请求失败后,Hystrix会让用户自定义备用方案。
- 断路器:决定了请求是否需要真正的执行,如果断路器打开,那么所有的请求都将失败,执行回退逻辑。如果断路器关闭,那么请求将正常执行。
- 指标监控:对请求的生命周期进行监控。
工作原理: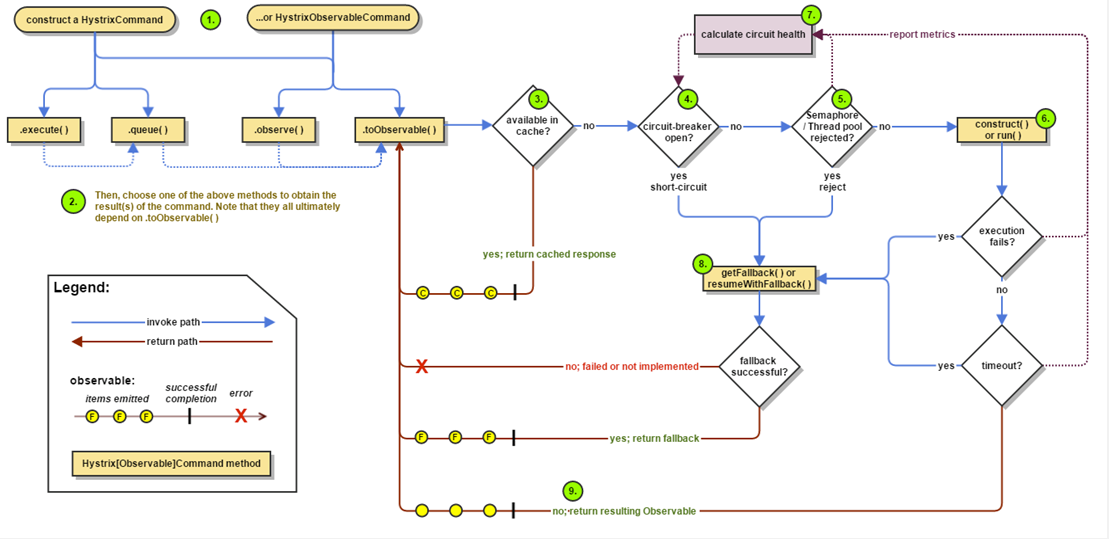
- 构建一个HystrixCommand或者HystrixObservableCommand对象,将请求包装到Command对象中。
- 执行构建好的命令。
- 判断当前请求是否有缓存,如果有就直接返回缓存的内容。
- 判断断路器是否打开,如果打开,跳到第8步,获取fallback方法,执行fallback逻辑。如果没有打开,执行第5步。
- 如果是线程池隔离模式,判断线程池队列的容量;如果是信号量隔离模式,会判断信号量的值是否已经被使用完。如果线程池和信号量都已经满了,同样请求不被执行,直接跳到第8步。
- 执行HystrixObservableCommand.construct()或HystrixCommand.run()方法,正在执行的请求逻辑就封装在construct()或run()方法中。
- 请求过程中,若出现异常或者超时,会直接到第8步,执行成功就返回结果。执行结果会将数据上报给断路器,断路器会根据上报的数据来判断断路器是否打开
- fallback
3.3 Hystrix使用
- HystrixCommand注解方式
- 在Feign中使用
- 在Zuul中使用
Hystrix配置: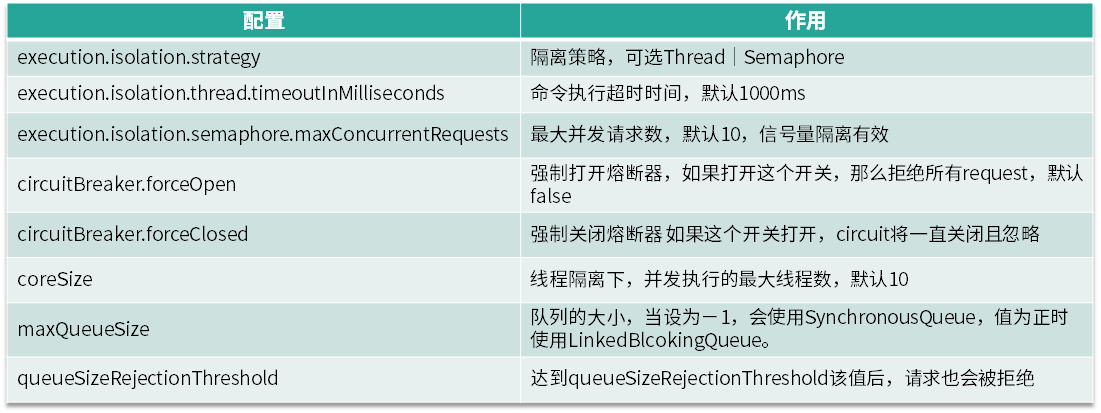
3.4 Hystrix隔离机制
线程池隔离:当用户请求A服务后,A服务需要调用其它服务,这个时候可以为不同的服务创建独立的线程池,假如A需要调用B和C,那么可以创建两个独立的线程池,将调用B服务的线程池丢入到一个线程池,将调用C服务的线程丢入另一个线程池,这样起隔离效果,就算其中某个线程池请求满了,无法处理请求了,对另一个线程池页没有影响。使用线程隔离。需要调整好线程池参数,否则和信号量一样,并发量大的时候性能上不去。设置最大线程数,默认为10,队列大小决定了能够堆积多少请求,但请求不能一直堆积,所有还需要设置一个阈值来进行拒绝。
信号量隔离:信号量就算一个计数器,如初始化是100,那么每次请求过来时信号量就会减1,当信号量计数为0时,请求就会被拒绝,等之前的请求处理完成后,信号量就会加1。起到了限流的作用,信号量隔离是在请求主线程中执行的。
线程池隔离的特点是Command运行在独立的线程池中,可以支持超时,是单独的线程,支持异步。信号量隔离运行在调用的主线程中,不支持超时,只能同步调用。
3.5 使用技巧
配置可以对接配置中心进行动态调整
回退逻辑中可以手动埋点或者通过输出日志进行告警
使用线程池隔离模式再用ThreadLocal会有坑
被隔离的方法会包装成一个Command丢入到独立的线程中执行,这个时候就是从A线程切换到了B线程,ThreadLocal的数据就会丢失。网关中尽量用信号隔离
插件机制可以实现很多扩展
Hystrix各种超时配置方式
commandKey、groupKey、threadPoolKey的使用
在使用HystrixCommand注解时,会配置commandKey、groupKey、threadPoolKey。commandKey表示封装的command的名称,可以给指定的commandKey进行参数的设置。groupKey是将一组command进行分组,如果没有设置threadPoolKey的话,那么线程池的名称会用groupKey。threadPollKey是线程池的名称,多个command的threadPoolKey相同,那么会使用同一个线程池。
4.Feign
Feign是一个声明式的REST客户端,Feign提供了HTTP请求的模板,通过编写简单的接口和插入注解,就可以定义好Http请求的参数、格式、地址等信息。Feign会完全代理HTTP请求,Spring Cloud对Feign进行了封装,使其支持SpringMVC标准注解和HttpMessageConverters。Feign可以与Eureka和Ribbon组合使用以支持负载均衡,与Hystrix组合使用,支持熔断回退。
4.1 重要组件
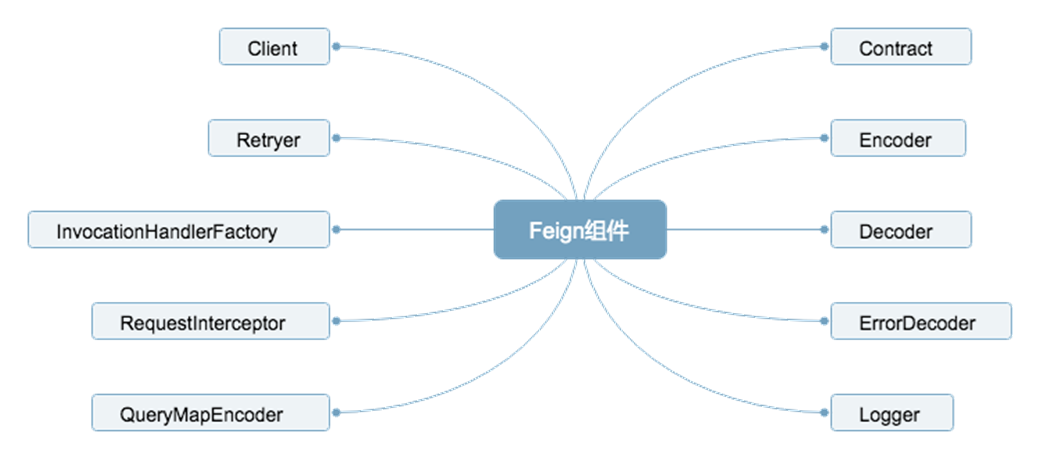
Contract 契约组件
Contract允许用户自定义契约去解析注解信息,如在Spring Cloud中使用Feign,可以使用SpringMVC的注解来定义Feign的客户端。Encoder 编码组件
通过该组件可以将请求信息采用指定的编码方式来进行编码后传输。Decoder 编码组件
Decoder将相应数据解码成对象。
ErrorDecoder 异常解码器
当被调用方发生异常后,可以在ErrorDecoder中将响应的数据转换成具体的异常返回给调用方,适合内部服务之间调用,但不想通过指定的字段来判断是否成功的场景,直接用自定义异常代替。Logger 日志记录
Logger组件负责Feign中记录日志的,可以指定Logger的级别及自定义日志的输出。Client 请求执行组件
Client是负责HTTP请求执行的组件,Feign将请求信息封装好后会交由Client来执行,Feign中默认的Client是通过JDK的HttpURLConnection发起请求的,每次发起请求的适合,都会建立新的HttpURLConnection链接,性能很差。可以扩展该接口,使用Apache HttpClient等基于连接池的高性能HTTP客户端。Retryer 重试组件
Retryer是负责重试的组件,Feign内置了重试器,当HTTP请求出现IO异常时,Feign会限定最大重试次数来进行重试操作。InvocationHandlerFactory 代理
IncocationHandlerFactory采用JDK的动态代理方式生成代理对象,定义的Feign接口,当调用这个接口中定义的方法时,实际上是去调用远程的HTTP API,这里用了动态代理的方式,当调用某个方法时,会进入代理中正在的去调用远程HTTP API。RequestInterceptor 请求拦截器
可以为Feign添加多个拦截器,在请求执行前设置一些扩展的参数信息。QueryMapEncoder 参数查询
QueryMapEncoder是针对实体类参数查询的编码器,可以基于QueryMapEncoder将实体类生成对应的查询参数。
4.2 Feign执行过程
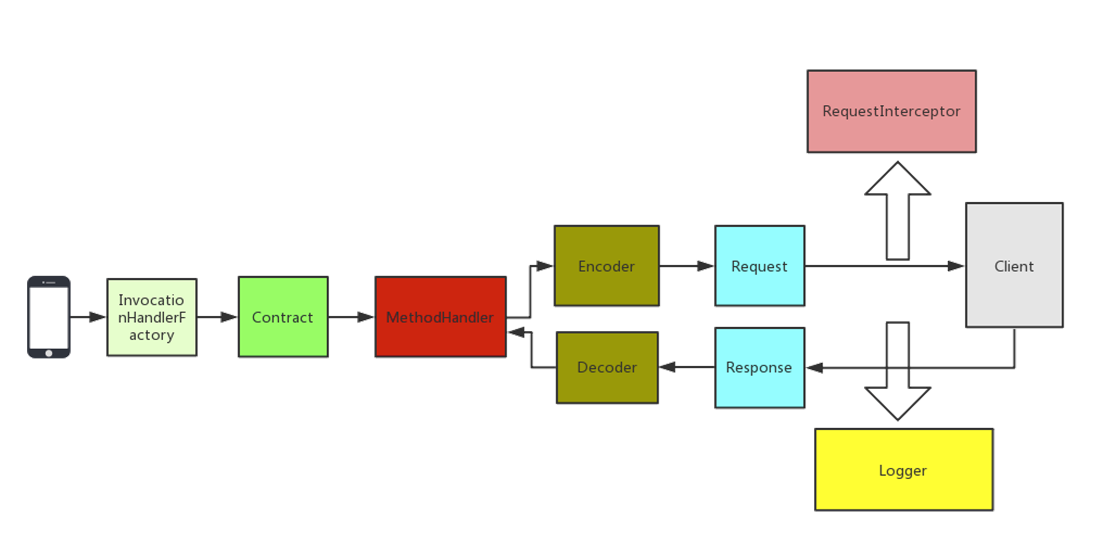
定义对应的接口类,在接口类上使用Feign自带的注解来标识HTTP的参数信息,当调用接口对应的方法时,Feign内部会基于面向接口的动态代理方式生成实现类,将请求调用委托到动态代理实现类,负责动态代理的组件是InvocationHandlerFactory。根据Contract规则,解析接口类的注解信息,翻译成Feign内部能识别的信息。Spring Cloud OpenFeign中就扩展了SpringMVCContract。MethodHandler在执行的时候会生成Request对象,在构建Request对象的时候会为其设置拦截器,交由Client执行前记录一些日志,Client执行完成后也记录一些日志,然后使Decoder进行相应结果的解码操作,并返回结果。
4.3 使用技巧
继承特性
将API的定义提取出来封装成一个单独的接口,给API的实现方和调用方共用。拦截器
添加自己的拦截器来实现某些场景下的需求,实现RequestInterceptor接口,在apply方法中编写自己的逻辑。GET请求多参数传递
一般超过3个以上的参数会封装在一个实体类中,在Spring Cloud Open Feign中要支持对象接收多个参数,需要增加@SpringQueryMap注解。日志配置
Feign日志级别:- NONE:不输出日志
- BASIC:只输出请求方法的URL和响应的状态码及执行的时间
- HEADERS:将BASIC和请求头信息输出
- FULL:会输出全部完整的请求信息
异常解码器
5.Zuul
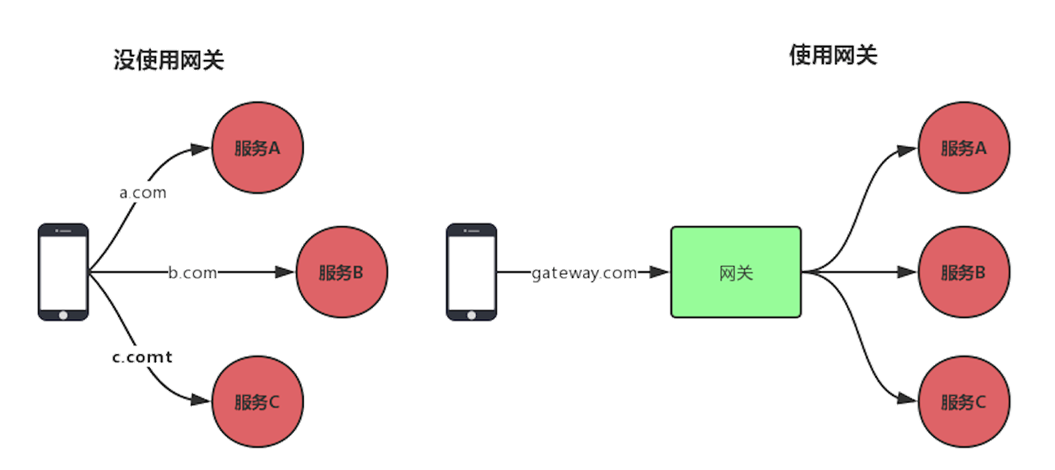
API网关是对外提供服务的一个入口,并且隐藏了内部架构的实现。可以为我们管理大量的API接口,负责对接用户、协议适配、安全认证、路由转发、流量限制、日志监控、防止爬虫、灰度发布等功能。
动态路由
![]()
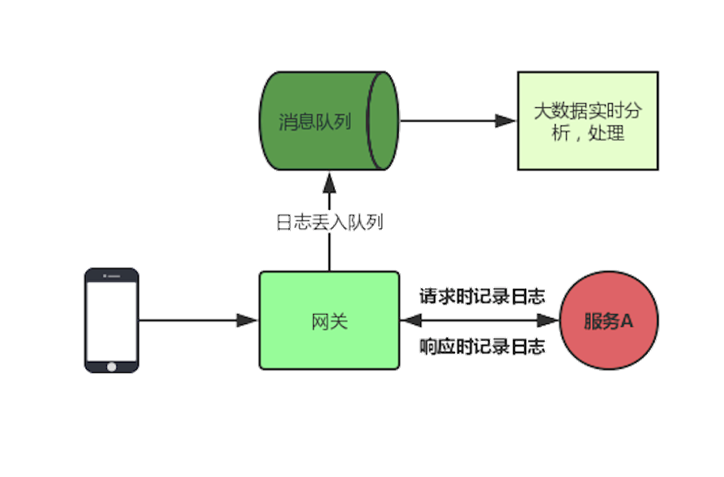
将客户端的请求路由到后端不同的服务上,如果没有网关去做统一的路由,那么客户端就要关注后端N个服务。请求监控
![]()
对整个系统的请求进行监控,详细的记录请求响应日志,可以实时的统计当前系统的访问量及监控状态。认证鉴权
统一对访问请求做认证,拒绝非法请求,保护后端的服务。压力测试
![]()
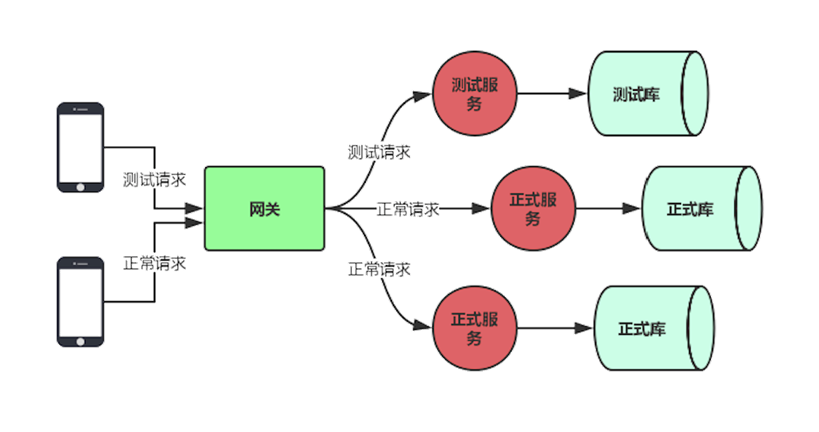
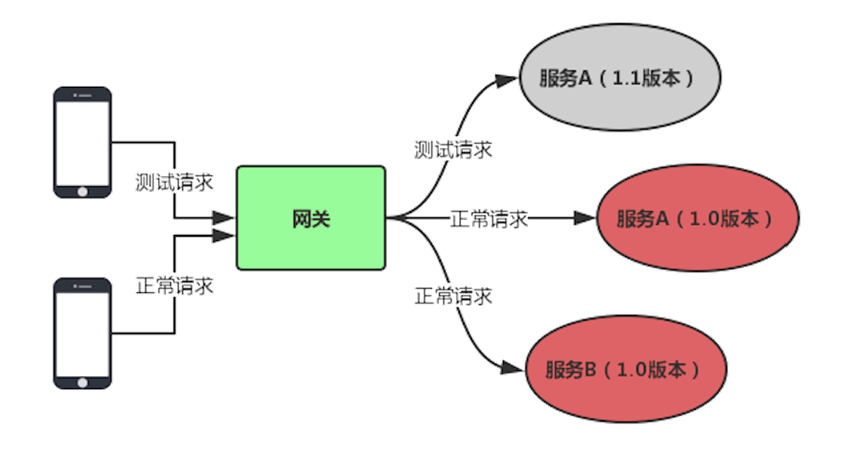
动态的将测试请求转发到后端服务的集群中,还可以识别测试流量和真实流量,用来做一些特殊的处理。灰度发布
![]()
当需要发布新版本时,通过测试请求对1.1版本的服务进行测试,若没发现问题,可以将正常的请求转发过来,若有问题,不影响用户使用的1.0版本。
5.1 过滤器
过滤器可以对请求或响应结果进行处理,Zuul支持动态加载、编译、运行这些过滤器。
- pre过滤器:可以在请求被路由器之前调用。适用于身份认证的场景,认证通过后再继续执行下个流程。
- route过滤器:在路由请求时被调用。适用于灰度发布的场景,在将要路由的时候可以做一些自定义的逻辑。
- post过滤器:在route和error过滤器之后被调用。将请求路由到达具体的服务之后执行,适用于添加响应头,记录响应日志等应用场景。
- error过滤器:处理请求发生错误时被调用。在执行过程中发送错误时会进入error过滤器,可以用来统一记录错误信息。
自定义过滤器:
继承ZuulFilter,然后重写ZuulFilter的四个方法
shouldFilter方法决定了是否执行该过滤器,true为执行,false不执行,可以利用配置中心实现动态的开启或关闭过滤器。filterType方法是要返回过滤器的类型,可选择为pre、route、post、error四种类型。过滤器可以有多个,先后顺序可以通过filterOrder来指定过滤器的执行顺序,数字越小,优先级越高。业务逻辑写在run方法中。
5.2 请求生命周期
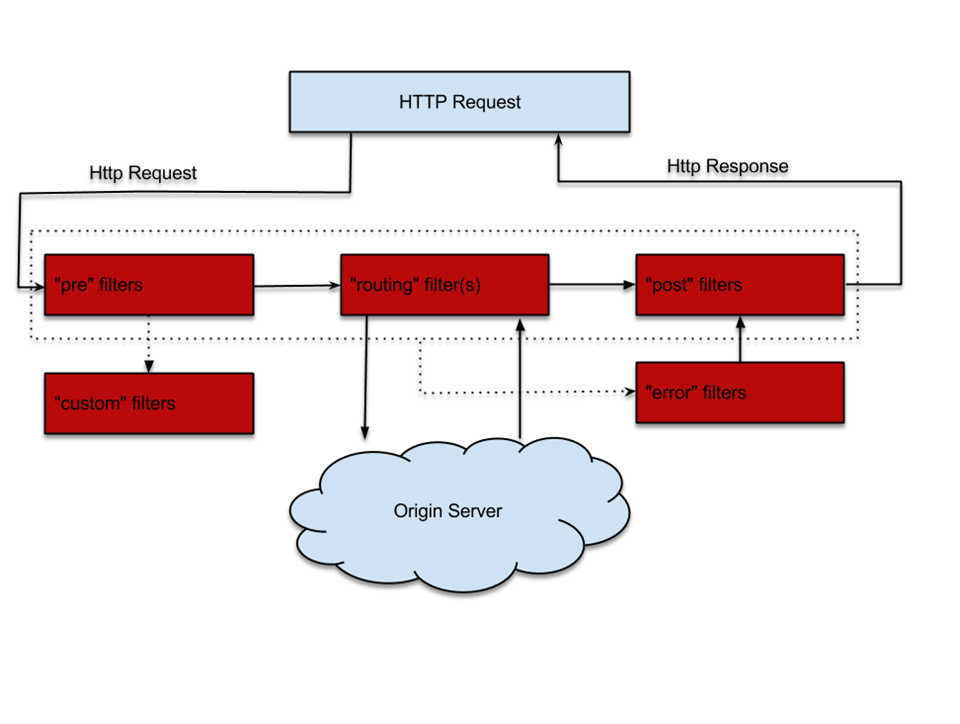
请求先进入pre过滤器,在pre过滤器执行完后,进入routing过滤器,开始路由到具体的服务中,路由完成后,接着到了post过滤器,然后将请求结果返回给客户端。如果过程中出现异常,则会进入error过滤器。源码对应ZuulServlet。
5.3 Zuul容错与回退
5.4 使用技巧
内置端点
当@EnableZuulProxy与Spring Boot Actuator配合使用时,Zuul会暴露一个路由管理端点/routes。借助这个端点,可以直观的查看及管理Zuul的路由。还有一个/filters端点可以查看Zuul中所有过滤器的信息。文件上传
通过Zuul上传文件,超过1M的文件会上传失败,配置max-file-size和max-request-size,Zuul中需要配置,最终接受文件的服务也要配置。或在网关请求地址前面上加上/zuul,可以绕过Spring DispatcherServlet上传大文件。Zuul服务不用再配置,但接收文件的服务还是要配置文件上传大小。在上传大文件时,时间较长,可以设置Ribbon的ConnectTimeOut和ReadTimeOut。如果Zuul的Hystrix隔离模式为线程的话需要设置Hystrix的超时时间。请求响应输出
Zuul Debug
跨域配置
关闭Zuul全局路由转发
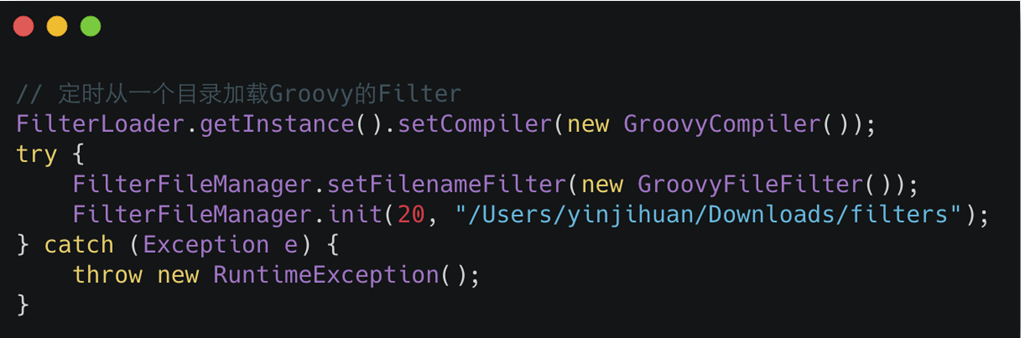
配置zuul.ignored-service=*关闭路由转发,配置zuui.ignoredPatterns忽略不想暴露的API。动态过滤器
定期扫描存放Groovy Filter文件的目录,如果发现有新Groovy Filter文件或者Groovy Filter源码有改动,那么就会对Groovy文件进行编译加载。首先在项目中增加Groovy的依赖,然后在项目启动后设置Groovy的动态加载任务,定时动态加载指定目录的Groovy文件。![]()